

目次
『データビジュアライゼーション玉手箱』連載の趣旨
『データビジュアライゼーション玉手箱』は、データビジュアライゼーションについて、さまざまなデータソースを取り上げたり、効果的な可視化・見える化の手法について試行錯誤した結果を共有するシリーズです。第3回となる今回は、データを活用する上での、データのあり方について考えてみましょう。
※第2回:データ活用に踏み切れない企業の特徴

データを活用する以前に問題が発覚
データを可視化や分析するなど、これからデータを活用をしていこうとする企業にお会いすると、かなりの確率で、データそのものが存在していなかったり、すぐには使えない状態だったりします。その場合はデータのあり方、持ち方についてアドバイスをすることになります。
データはそもそも企業の資産なので、この定義は実はかなり重要なことであり、厳密に考え、実践し、継続的に運用していく必要があります。
ワイド型を使っているケースは意外と多い
Excelでデータを作成している多くのケースで見られるのが、下画像のような「ワイド型」データです。ワイド型データとは、条件の違い(この例では年度)は横並び(列)で、グループ(この例では支店)の違いは縦の並び(行)で区別されるタイプのデータです。つまり、データが増えていくと横に増えていくので、ワイド型と呼ばれます。

最終形・完成形のデータとしてはよく使われる見せ方です。視認性も良いので便利と言えば便利です。ただ、このワイド型は加工したり統計分析、可視化には向いていません。
例えば、下画像のようにBI/ダッシュボードを使って時系列で支店ごとの売上の推移を見る場合などは、ワイド型データで作成できるでしょうか?ワイド型データではとても作成しづらいことがわかります。
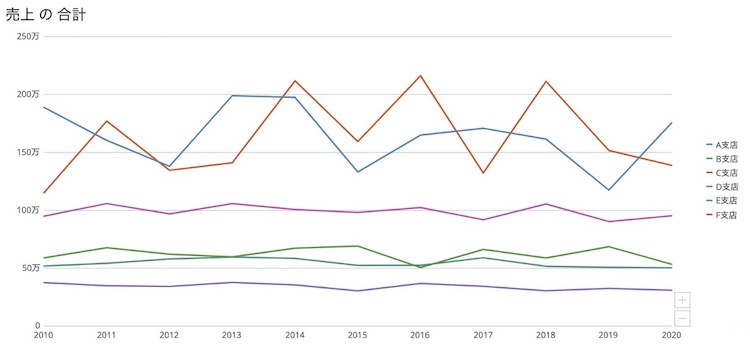
また、データを蓄積していく観点ではどうでしょう。日付が年別ではなく日別だった場合、ワイド型で持てるでしょうか?ワイド型では列がいくらあっても足りず、視認性、操作性も悪くなります。よって、蓄積にも向いてない形と言えます。
データ活用にはロング型
一方、ロング型データは、ひとつの列(この例では売上の列)のみがデータ(従属変数またはメトリクス)を表し、他の列はすべてこのデータの性質(ディメンション:この例では年度、支店)を表しているタイプのデータです。
この形式では、異なる条件(例えば地域)が増えると横に列が増えますが、データが蓄積されると縦方向に大きくデータが伸びていきます。データが増えた場合(例えば利益)に切り替える際も、完全に別のデータを準備せず、D列に足せばいいわけです(売上と利益から利益率を計算することも簡単)。ワイド型のように、売上と利益で別々の表を用意する必要もありません。
パッと見た際の視認性はワイド型に比べると低いかもしれませんが、データの蓄積には向いています。集計単位が日別、月、年度の場合でも集計しやすく、加工、統計分析、可視化など、データ活用には非常に向いている形式です。
表記のゆれにも注意
「表記のゆれ」とは、同じ意味を持つ言葉について、表記が混在している状態を指します。特に日本語は表現方法(ひらがな、カタカナ、漢字、ローマ字など)が豊富ということもあり、起きやすい現象です。同じことを書く場合でも、人それぞれに書き方が多様なのです。
表記ゆれがあると、「名寄せ」などのグルーピングや集計、データの突合ができなくなるので注意が必要です。
「表記のゆれ」の防止策として、社内で表記ルールを作成して遵守しましょう。その際、ひらがな、カタカナ、漢字、ローマ字を使うのか、全角か半角か、大文字か小文字か、スペースは入れるのか入れないのかなどの細かい点にも留意しましょう。
以下は例ですが、何を「正」とするかはルール次第なので、あくまでも参考までに。表記のゆれが企業名一つをとっても起きやすいということを意識してください。
表記のゆれの例1
○ アタラ・システムズ株式会社
× アタラシステムズ株式会社
× アタラ システムズ株式会社
× アタラシステムズ(株)
× アタラシステムズ
× ATARAシステムズ株式会社
× 株式会社アタラシステムズ
表記のゆれの例2
○ ATARA商事合同会社 (半角)
× ATARA商事合同会社 (全角)
IDを付与する
前述した日本語の表記のゆれ問題とも関連しますが、データを一意で区別して他のデータと突き合わせるような場合にはID同士での突き合わせを行うことをおすすめします。取引先、支店、商品など重要なディメンションIDがない場合はルールを決めて、IDをデータに含めていくことも検討しましょう。
IDの決め方で留意すべき点
- IDの命名ルールは英数字を使う
- IDを文字列として認識させるため、先頭に文字列(A〜Z)を使う
- IDは最低14桁と長めにもっておく
- IDには意味を持たせない
例) A1012323304890
データフォーマットやネーミングルールを決める
Excelなどのアプリケーションで作成したデータをBIツールやダッシュボードで活用する場合、ファイルのフォーマットが正しくないと取り込めないケースもあります。以下は汎用的なものですが、自社のアプリケーションや環境によってルールを決めましょう。
CSVのフォーマットルールの例
- カンマ区切り
- ヘッダ行有り
- 小計、合計行なし
- 日付、日時のフォーマットは西暦とし、漢字は含まないようにする(YYYY-MM-DDまたはYYYY-MM-DD hh:mm:ss)
- 「”」「,」「\」などのESCAPE方法はEXCELに準拠
- 文字コードはUTF-8(BOM無し)
- ファイル名も英語(英数字、スペースなし、拡張子あり)を推奨
教育、メンテナンスの重要性
ルールを決めたとしても、使うのは人なのでどうしてもルールに沿っていないデータが出てきてしまいます。ルールの徹底も大事ですが、なぜ大事なのか、データを蓄積するとどういうメリットがあるのか、ということも含めたエデュケーションが重要です。
また、データのモニタリングや補正、クリーニングを行う担当者のアサイン、評価をすることもおすすめします。ゆくゆくはデータの補正やクリーニングに関しても自動化する機構を取り入れることも可能です。より効率的に、企業資産となるデータを蓄積し、ビジネスインパクトはあるデータ活用を目指して欲しいと思います。
バックナンバー


