多くの企業やテレビ局は、次にブレイクするタレントを早めに発掘し、最大限活用したいと考えます。これまで以上にデータを駆使し、キャスティングに役立てるためのデータとは。その活用法とは、についてエム・データの薄井司さんにお話を伺いました。
話し手:
株式会社エム・データ
取締役/ストラテジックプランニングディレクター
薄井 司さん
聞き手:
アタラ合同会社 CEO 杉原 剛
※このインタビューは2018年2月23日に実施されました。
「Talent Rank」で、タレントのパワーを可視化
杉原:エム・データさんには、2015年にUnyoo.jpの記事で一度お話を伺いました。前回の内容を踏まえ、まずは今年1月31日にβ版をリリースされた「Talent Rank」について教えていただけますか。

薄井:「Talent Rank」とは、タレントのパワーを可視化することでネクストブレイカーの予兆を先取りし、キャスティングなどに活用する目的で開発されたツールです。
テレビ局のプロデューサーや各社のキャスティングに関わる方は、テレビにはほとんど出演していないがネットで急上昇しているタレントに注目しています。こうした人物を先取りすることでネクストブレイカーに繋がるという趣旨で「Talent Rank」は作られています。具体的にはテレビの露出軸をTVメタデータ(テレビの放送内容をテキスト化したもの)を用い、それに対する視聴者の反応軸をTwitterなどのネットデータを指標化してタレントパワーランキングを出す仕組みです。
様々なデータの統合分析で、マルチデータを掛け合わせてひとつのダッシュボードに落とし込むというコンセプトで作っているクラウド型ビッグデータ分析サービス「TV Rank」シリーズのひとつのメニューという位置づけです。
杉原:「TV Rank」のタレント編というイメージですか?
薄井:その通りです。現在はβ版を予定しており、今年の夏頃に正式ローンチすべく開発を進めているところです。「Talent Rank」は主にテレビ局のプロデューサーや各社のキャスティング担当者、タレントさんを売り込みたい芸能事務所の方とコミュニケーションし、彼らの感じている課題やニーズに沿って開発しています。分析の機軸となるメインデータは弊社が提供するTVメタデータと提携企業のネットのデータを使い、独自のロジックでスコアリングします。
杉原:それぞれにスコアの重みが異なるのでしょうか?
薄井:そうですね。番組のデータに対してキャスティングされた出演者を「出演量」でスコア化したものと、ニュース・ワイドショー等で取り上げられるケース、つまりキャスティングとは異なる番組露出を「話題量」として、CMの出演を「CM量」として、これに「Twitterや検索量」を加え偏差値化し各種ランキングなどのメニューを構成します。(※検索データは、今後オプションで追加予定)
杉原:御社が提供されているTVメタデータの中のフィールドからタレント名をテキストマイニングをするということでしょうか。
薄井:はい。弊社がこれまで蓄積してきたタレントなどテレビ出演者の人物辞書をベースに、番組の出演なのか話題なのか、CMなのかを区別します。これにTwitterの人物に関する投稿の全量データを加え、世の中がどれだけ当該タレントや人物に関心を持っているかを測っています。
標準メニューはウィークリー更新で、今後、マンスリー更新のリッチ版も計画しており、これには検索データや視聴データ、YouTubeの再生数などを加えてウエイト付けをしたり、取得できるようになればインスタグラムのデータも加えて多様な影響力を科学したいと思っています。

「Talent Rank」では、タレントパワーランキングだけでなく、その時々の話題に上った人物に対して個別に、どういう属性の人が興味を持っているのか、対象人物名とともに検索されたセカンド検索キーワードやTwitterの共起語も見ることができます。例えば、舞台女優の方などでテレビにはまったく露出しませんが、検索やTwitterでは上位に来ることがあります。その方の支持層もわかるので、例えば40代の女性に圧倒的に人気のある方だとわかったら、40代女性をターゲットにした番組に出演していただいて視聴率を取ろうとか、40代女性をターゲットにした商品の広告主がターゲットにメッセージを伝える際にはこの方を起用すると効果が出やすい、といった仮説を立てることができます。
また、タレントの名前とともに検索されているセカンド検索キーワードは、「Twitter」や「ブログ」といったワードが圧倒的に多いです。これは裏を返せばこの人に会いたい、この人のことをもっと知りたいという欲求が働いているということです。ならば、逆引き的に「ブログ」や「Twitter」とともに検索されるタレントでランキングを出してデモグラ別に支持層を判定できれば、面白い発見を得られる、といった使い方もできます。
杉原:ここまで細かく分析できれば、とても面白いですね。これには検索のデータを使われているのでしょうか?
薄井:はい。検索データを連携する開発を進めており、検索ワードの取得企業や調査パネルを保有するリサーチ会社からデータを入手しています。ブログ内検索ではなく、Yahoo!やGoogleで「ブログ 〇〇」といった内容で検索された際のセカンド検索キーワードを抽出し反映させます。
現在検討中の事項がもう一つあるのですが、横軸にテレビでの露出量、縦軸にTwitterの投稿量でタレントのポジショニングマップを表現した際、パワーや影響力を現す円の大きさをCMの量にするのか、検索にするか、あるいは視聴データやYouTube再生数などにするかということです。SS(スーパースター)ランクのタレントさんは一目瞭然ですが、注目したいのはテレビ露出は少ないが、バズが伸びている方です。そういう方を発見して早めに起用し、その方が出演される番組についてSNS上に投稿してもらえば、拡散されやすくなり、番組の視聴活性やCM効果が期待できます。ネガティブなバズを持つ方もいらっしゃるので、ポジネガを区別する必要はあるのですが、バズ持ちタレントさんの推測や先取りも可能になります。
狙い目は隠れたバズメイカー
杉原:では、実際の使い方について教えてください。
薄井:β版の場合、ログインするとまず総合ランキングが表示されます。デフォルトは全ジャンルの1万名近い人物が混在したランキングになっていますので、それらを人物ジャンルごとにセグメントします。TVメタデータが保有する人物マスターを使って、 アイドルや俳優、お笑い芸人、モデル、ミュージシャン、スポーツ選手、キャスター・・・だけでなく、政治家、文化人、ユーチューバーなどのジャンルで、調べたい人物ジャンルをセグメントすることができます。勿論、調査したい期間の指定も簡単にできます。
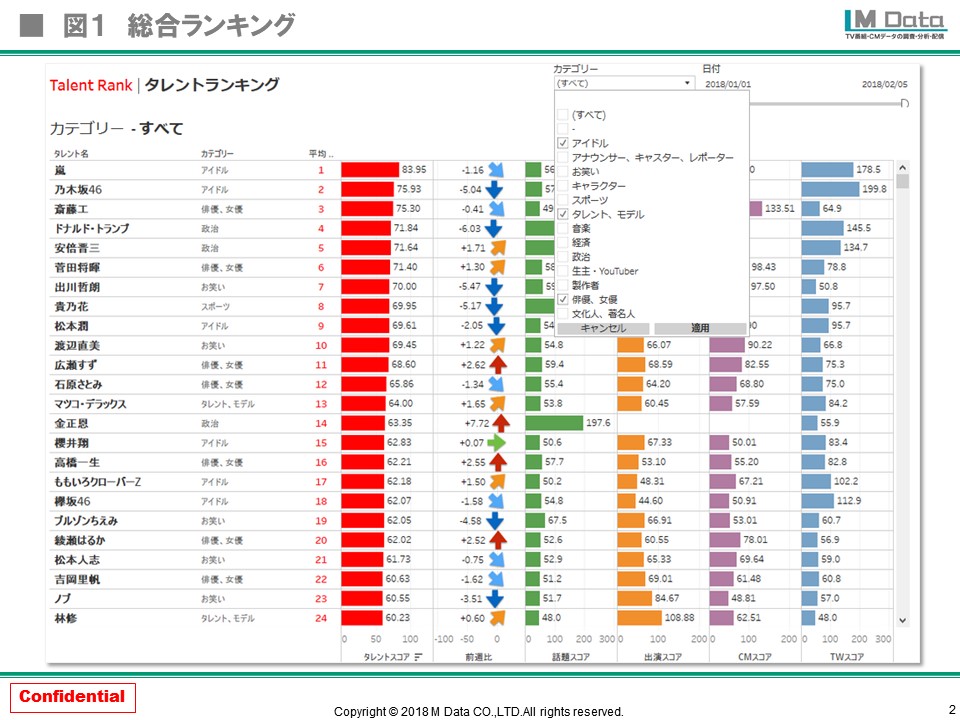
(クリックして拡大)
先ほども述べたようにプロデューサーやキャスティング担当者がもっとも知りたいのはネクストブレイカーをキャッチできる情報です。ですので、テレビ番組やCMの出演が少ない人物をある偏差値ライン(ユーザーが自由設定)で足切りし、Twitterなどネットの話題が急上昇している人物でランキングするネクストブレイカー発掘メニューも作りました。この場合、ネガティブな話題で上位に来る可能性にも配慮し、ポジネガ判定表示も機能化しています。
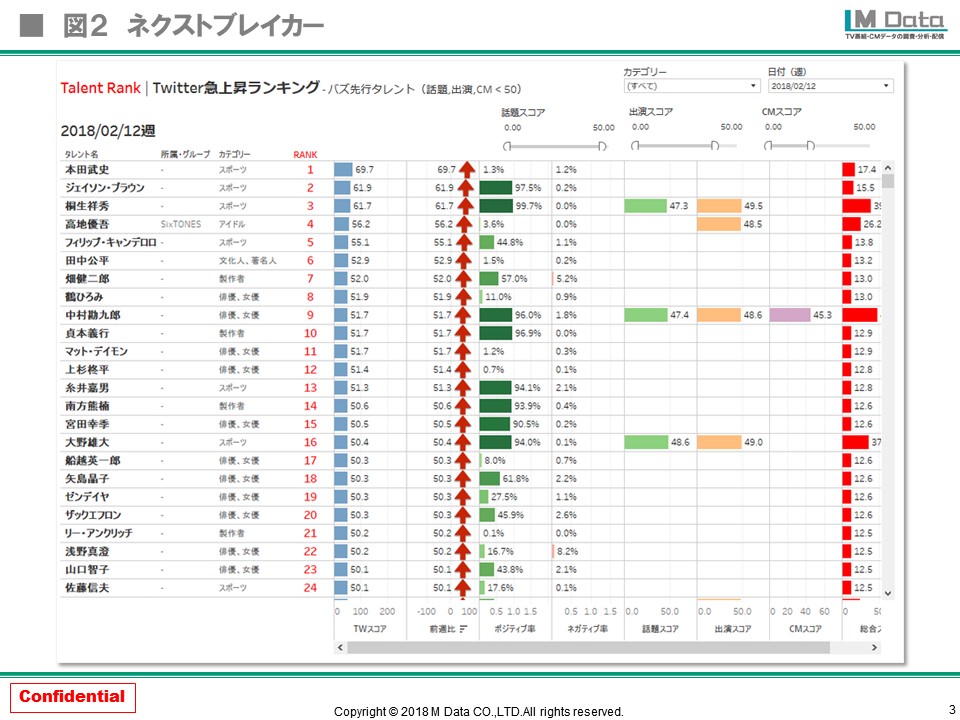
(クリックして拡大)
タレント個別の詳細情報が検索・確認できる分析メニューも用意しており、「ジャンル・職業/性別/グループか個人か/所属先/生年月日/スコアとランキング/時系列トレンド/ポジネガ判定/支持層の男女比・デモグラ別支持率/人気エリアのヒートマップ/共起語」といった詳細情報が確認できます。加えて、実際にどの番組やCMにどれだけ、どのように露出したかも生データで確認できます。
杉原:御社のメタデータはオペレーターの方が打ち込んでいると思うのですが、Twitterでのツイートや検索キーワードは言葉の表記の揺れが生じませんか?どのように吸収されているのでしょうか?
薄井:パートナーである株式会社角川アスキー総合研究所さんが保有するエンタメ系の辞書やタレントマスターを活用し、株式会社NTTデータさんから提供されるTwitterデータをクレンジングしているため、データが精緻化されます。それをTVメタデータの人物マスターと統合し、名寄せをして、表記揺れを吸収しています。
また、Twitterのプロフィールをベースにして、あるタレントが今この瞬間どのエリアで人気があり注目されているかもわかります。例えば地方局さんではなかなかメジャータレントを起用できないため、例えば地方発で盛り上がり、だんだん全国に人気が拡大してきたタレントをアニメーションでとらえ、ブレイク前のローカルタレントをキャッチすることができます。ユーチューバーや生主などはその動きが顕著です。
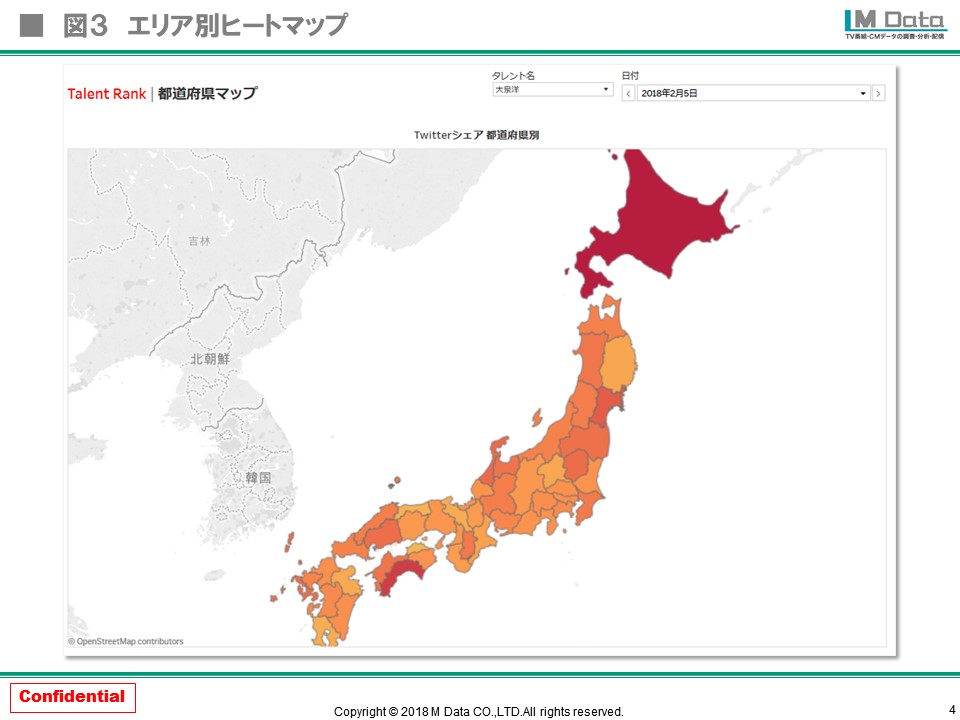
(クリックして拡大)
杉原:面白いですね!ネクストブレイカーを地域別で見て、例えば九州だけでフィルタリングしてみたら、やたらホットだった、といった状況が一目でわかりますね。
薄井:はい。地域に加えて男女10~60代までのデモグラ別支持率を見ることもできたり、全国平均に対して各都道府県でどの程度平均とのギャップがあるのかといったことがわかります。本当はここに検索やYouTube、インスタグラムのデータを入れるとさらに異なる指標が見えてくるのかな、と思います。
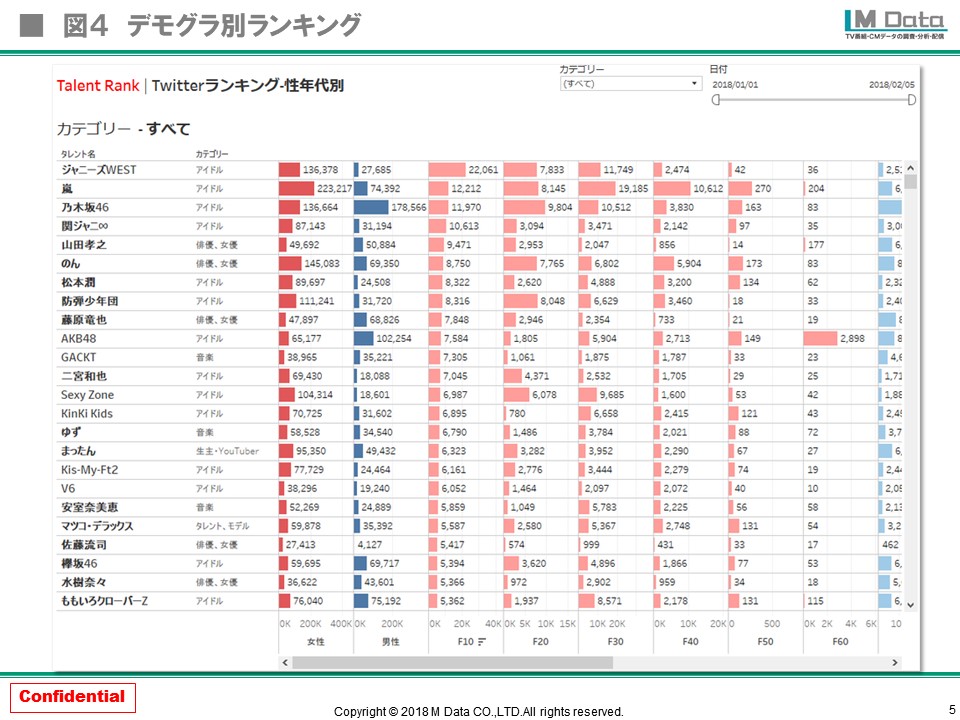
(クリックして拡大)
後はポジションについてですが、これには面白い傾向が出ます。
やはり出始めのタレントの方は、平均値以下のゾーンに集中し埋もれてしまいます。少し認知率が高まるとバズがつきはじめ、それに伴いテレビの露出が増え、さらにバズを加速させ「バズメイカー」のゾーンに入ってきます。ここに大きなキャズムがあり、ブレイクできるかのポイントになるのですが、キャズムを超えられると「スーパースター」の領域に入ってきます。そこからテレビ出演が増え、レギュラー番組などが多くなるとバズが落ち着き「ブロードキャスター」ゾーンに定着します。現実的には、なかなかここまでくる方は少ないのですが、テレビ局の番組制作の方は、まずは「バズメイカー」の兆候やトレンドにある人物をいかに先取りし、やがてキャズムを超えるタレントをキャスティングできるかが、人選の妙になるのかなと思います。
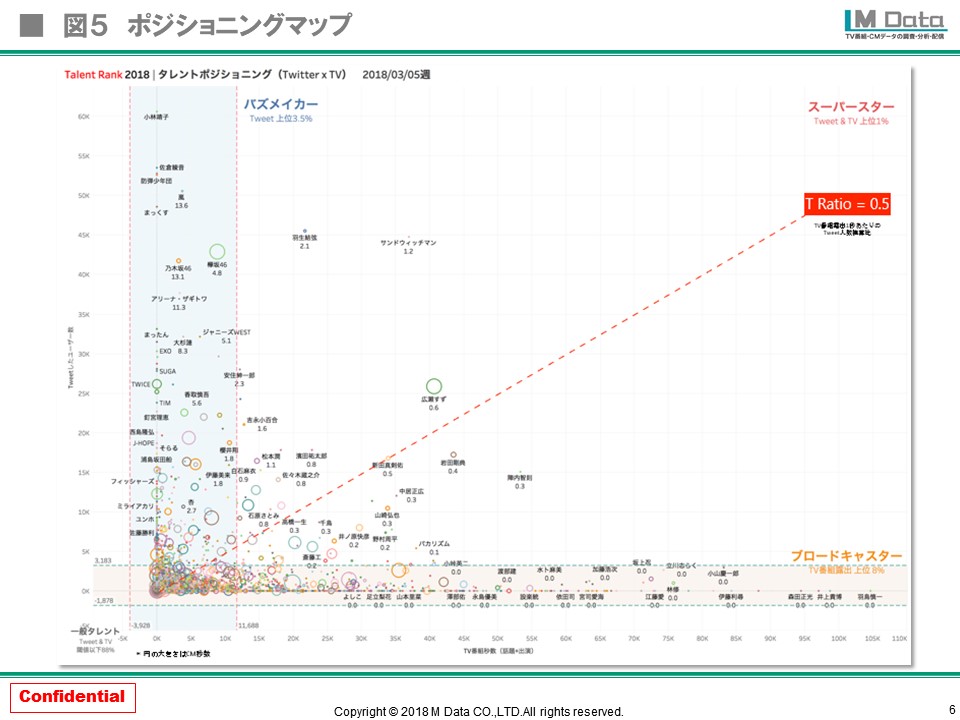
(クリックして拡大)
ちなみに、アイドルの場合はブレイクの法則があります。複数のアイドルグループで検証した結果、各アイドルの番組露出時間が、NHK2局と民放キー5局の合計で、週100分を超えると国民的アイドルとして認知され、支持されるということがわかってきました。図にあるように、「AKB」も「ももクロ」も週100分を超えるとその年の紅白歌合戦に出場が決まり、時の総理大臣に桜を見る会に呼ばれています(笑)
我々はこれを「週100分の壁」とよんでおり、このような様々な法則をTalent Rankで研究し、選挙やブレイクタレント、ヒット商品や需要・トレンドなどの予測に応用していきたい考えです。
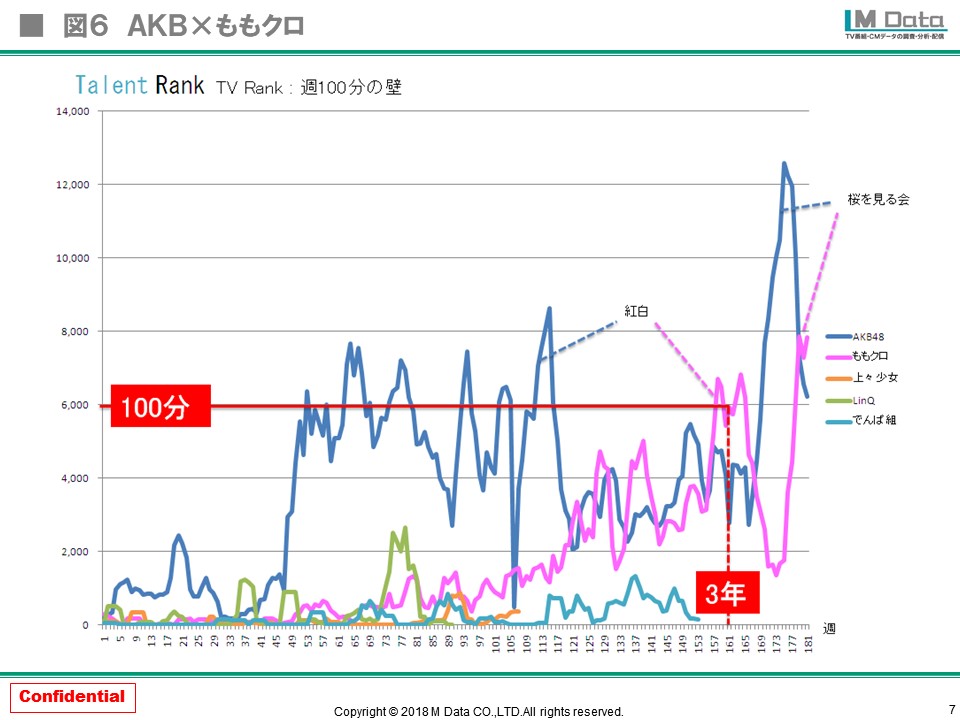
(クリックして拡大)
これは一例ですが、「Talent Rank」ならばこういったことが見える化できるのです。
広告主からの依頼では、CMのタレントをキャスティングする際に、トレンドになっている俳優が誰なのか、まだブレイクしていないアイドルを採用するべきか、急上昇中のモデルは誰なのかなどのニーズに対し、その選択肢をご提示できます。
AIでの予測やスマートスピーカーへの対応も
杉原:今後正式版の開発を進めるにあたり、どのような機能を追加させていくご予定でしょうか?
薄井:ひとつはレポーティングサービスを計画しております。働き方改革を受け、忙しい方にはダッシュボードを操作する時間すら割けない課題もあるので、必要な分析結果のみを一目で確認できる四季報や月報・週報なども検討中です。
もう一つは、マルチデータ統合分析にAIを絡め、タレントレイティングやキャスティングされた人物の組み合わせでの番組パワーやCM効果、視聴率などの予測できたら面白いのではないかと考えています。
杉原:やはり予測の方に行かれるのですね。タレント視聴率は御社のデータですべて取るのでしょうか?
薄井:外部のデータと連携する必要があり、現在検討をしています。
また、このようなパッケージ商品を提供することに価値を感じていただける一方で、各ユーザーごとに自社保有データを加えたり、オリジナルメニューを作りたいという要望もあります。それらの要望にも柔軟に対応できるよう、汎用のBIツールを採用し、高額な開発費や導入費などを発生させないようにしているのも、それらの外部データ連携の容易さのためです。
杉原:AIのエンジンも各社さんが適宜選ばれると思います。そしてそれに合うように、御社にしかないデータを提供すると。
薄井:TVメタデータをDMPにコネクトし、それぞれの視聴系のデータや調査データ、SNS、ネットの行動ログ、位置情報や移動履歴、POSなどの購買データをシンクして統合されたデータをダッシュボードにアウトプットし、AIで予測するという流れができると思います。各AIに適応するデータは意識していますし、今後は視聴系のデータだけでなく、スマートスピーカーの音声ログも対象になってくると予測します。
杉原:スマートスピーカーが今後は間違いなく入ってきますよね。今どのスマートスピーカーもテレビの操作が可能ですよね。
薄井:そうですね。スマートスピーカーが連携されると、スマートスピーカーやスマートフォンとテレビをペアリングして、テレビの前にいる個人や、声で指示を出した人が特定できるようになります。つまり、シングルソース化できる可能性が出てきます。大量の会員IDやネットの行動ログがこれらの視聴データとマージして、「テレビとネットとリアル行動(移動や購買)」をシングルソースにした膨大なマーケティングデータが構築されると思います。
今回は「Talent Rank」の機軸でお話しましたが、「TV Rank」シリーズ全体として、様々な外部環境の変化がある状況においてもマルチデータ統合というポジションを担っていきたいと考えています。
杉原:我々がいつも話題にするのは、デジタル施策とテレビ施策の統合分析の話です。しかし、テレビもデジタルもどちらもしっかりとできている所はほとんどありません。でも事業主さんに伺うと、皆さんそこは取り込まなければいけないという危機感を持っていらっしゃいます。一歩踏み込んだ動きができる時代は、意外と早く来ると思われますか?
薄井:日本におけるスマートスピーカーの普及やその速度は分かりませんが、その間にも様々なサービスやテクノロジーでデータの取得や統合環境は進むと思います。 特にグローバルサービスにおけるデータドリブンの考え方やデジタルシフトのトレンドを捉えると、またトータルオーディエンスでの様々な視聴計測やメディア接触調査、視聴ログの普及、視聴データと会員情報の連携の動きを見るだけでも、想像よりも加速度的な環境変化は予測できます。

杉原:ちなみに「Talent Rank」はテレビ局さんが使うイメージですよね?
薄井:はい。テレビ局を中心にTV Rankシリーズで既にサービス中の「CMデータ編」と「番組データ編」はご活用いただいておりますが、今回のTalent Rankは番組のプロデューサーや編成マーケティングの方のご期待が高い他、番組制作会社、キャスティング会社、広告会社、調査会社、広告主などのキャスティングに関わる方のお引き合いが多いです。意外なところでは、タレントを売り込む立場の芸能プロダクションさんから、Talent Rankの指標を把握してプロモートに活用したいニーズをいただきました(笑)
また、Talent Rankはテレビ局向けにタレントパワーを指標化する目的ですが、相手がメーカー(広告主)になると、これがブランドパワーに置き換わり、統合するデータもPOSデータなどになります。そのニーズを受け、TV Rankシリーズでは「ブランド編」というテレビの露出効果を視聴者の態度変容やブランドリフト、CMのROIといった指標でスコアリングするメニューも構想しています。
杉原:共通するデータソースを使うのですが、プレイヤーが誰かによって加工の仕方や最終的なアウトプットの仕方が結構変わってくるというのが面白いですね。御社としては1つ1つに対応するよりもデータプロバイダーになって、外部にソリューションプロバイダーやインテグレーターがいるという状況になれば、様々なパターンにはめ込んでいけそうですよね。
また、ダッシュボードツールは結局ツールでしかないと思います。データの設計がきちんとまとまれば、必然的に見せ方はきまってくる。中間の部分をどう設計するかが、どう考えても肝になると思います。その部分を担うプレイヤーが今はそんなにいないかもしれませんが、環境や技術的な所がわかる人がいれば、今後出てくる可能性は大いにある。さらに要素となるデータが徐々にそろい始めているから、今後はさらに面白いことになるのではないかと思っています。
薄井:まったく同感です。ましてやマスというか、オフライン(特にテレビや売上)は今まで分断されていたものでしたが、データ統合ロジックによりシングルソース化されてくるという環境の変化が大きいのではないかと思います。それがより一層実現してくれば、個人に焦点を当てた精度の高い分析が可能になりますよね。そのうち、テレビCMもパーソナライズされて、見ている視聴者によってクリエイティブを出し分けるのが当たり前の世の中がやってくるかもしれませんし、データの統合分析もライブでモニタリングされるようになってきますね。
杉原:タイムリーに分析など、活用することが可能なTVのデータが揃ってきて、とてもおもしろい状況になってきましたね。興味深いお話をありがとうございました!